Model free vs Model-based Reinforcement Learning
There are many different reinforcement learning (RL) algorithms. One of the ways you can categorize RL algorithms is whether they use a model or not. You can think of a model as understanding of how the system changes when you perform an action. For example, suppose you are picking up an object from one place and drop it in another place. You understand the physics and can guess where your hand will be when you moved it right. That understanding of the state change is equivalent to “model” in reinforcement learning.
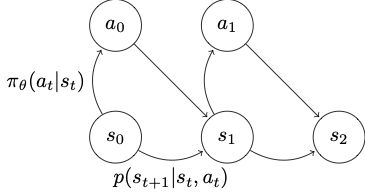
Going back to the markov diagram, we can say the probability of seeing a particular rollout \(\tau = ((s_1, a_1), (s_2, a_2), ...)\) is
\[p(\tau) = p(s_1)\prod^T_{t=1}\pi_\theta(a_t \vert s_t)p(s_{t+1} \vert s_t,a_t)\]Note this term \(p(s_{t+1} \vert s_t,a_t)\), transition probability distribution. This term provides what the next state is going to be given the current state and action, which matches our definition of a model.
Model-free
In the model-free approach, we do not try to learn \(p(s_{t+1}\vert s_t,a_t)\); we just watch the states change during the sampling phase. In other words, \(\tau\) is given to us.
Model-based
In the model-based approach, we try to learn this transition probability distribution and use it in improving your policy as well.
So why would one use a model-free vs model-based algorithm, and why are there different approaches?
Sampling efficiency
Needing fewer samples to train a good policy is an advantage. Here, model-based reinforcement learning has advantage; since you will learn how the state changes given action as part of the algorithm, you don’t need to generate new samples when the policy changes. For example, if you were training a policy that moves an object with a robot arm, and your policy put the arm in a place it’s never been, you would want to run a physical simulation or have the arm move in the real environment to make an observation of what happens, e.g., it bumps into the wall, knocks off another object, etc. Humans gain understanding of physics, so we can guess that when our hand moves and makes contact with an object with enough momentum, e.g., a vase, we will knock it down without ever having to do that ourselves. (Maybe young humans don’t, because they are still busy generating samples…)
Stability and Training Efficiency
Stability is a big issue in reinforcement learning. In supervised learning, we optimize the objective function almost always with gradient descent. In reinforcement learning, we often don’t; we use other approximations, such as with value functions (what’s the expected total reward in a given state) and how well the model fits. Here, it’s hard to say one is better than the other. Model-based RL algorithm has the issue that we’re optimizing for the fit of the model with gradient descent, rather than the rewards, the true objective of reinforcement learning, and a good model doesn’t necessarily result in high rewards. Policy gradient method, which is model-free and optimizes the rewards directly, tends to converge very slowly in many cases.
Understanding the two different approaches was a preview to understanding different RL algorithms in depth. In the next post, I’m going to go over the details of different RL algorithms.